
The AI race hit a new milestone on May 28, 2026, when Anthropic launched Claude Opus 4.8 — its fastest release cadence yet, just 41 days after Opus 4.7. Benchmark numbers landed almost immediately, and the results paint a clear picture: Opus 4.8 beats GPT-5.5 and Gemini 3.1 Pro on most major tests, but the story is more nuanced than a single leaderboard ranking.
This article breaks down exactly where each model wins, where it loses, and — crucially for Indian developers, startups, and enterprise teams — which model you should actually route your workloads to.
What Changed with Claude Opus 4.8?
Anthropic’s own framing is telling: Opus 4.8 is “a modest but tangible improvement” on its predecessor. That honesty is itself a product feature. The two headline improvements are:
- Sharper agentic performance: better at working independently over long tasks without constant human check-ins
- Improved self-honesty: roughly 4x less likely than Opus 4.7 to let coding errors pass unremarked, and more likely to flag uncertainty rather than confabulate
| 📌 Key context: Benchmark scores reflect capability ceilings. Real-world performance depends on task type, context length, and how you prompt the model. Use the data below as a routing guide, not an absolute ranking. |
Head-to-Head Benchmark Comparison
All benchmark data sourced from Anthropic’s official system card (May 28, 2026) and third-party analyses. GPT-5.5 figures from Anthropic’s published comparison chart and corroborated by independent evaluators. Gemini 3.1 Pro scores from Anthropic’s system card and DataCamp analysis.
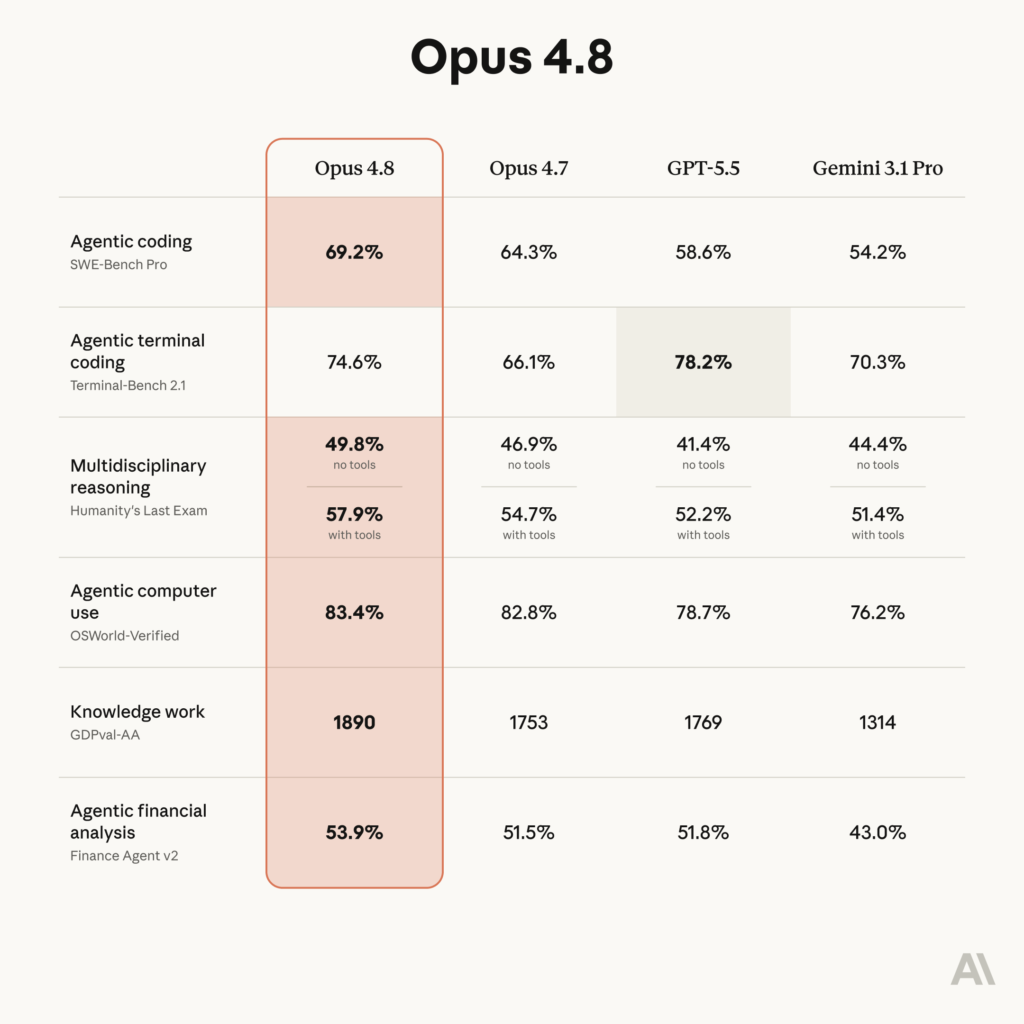
| Benchmark | Opus 4.8 | Opus 4.7 | GPT-5.5 | Gemini 3.1 Pro |
| SWE-Bench Pro (Agentic Coding) | 69.2% | 64.3% | 58.6% | 54.2% |
| SWE-Bench Verified | 88.6% | 87.6% | N/A | N/A |
| Humanity’s Last Exam (w/ tools) | 57.9% | 54.7% | ~52.2%* | ~51.4%* |
| OSWorld-Verified (Computer Use) | 83.4% | 82.8% | 78.7% | 76.2% |
| Terminal-Bench 2.1 | 74.6% | 66.1% | 78.2% | 70.3% |
| GDPval-AA (Real-World Agentic) | 1890 Elo | — | 1769 Elo | — |
| MCP-Atlas | 82.2% | — | 75.3% | — |
*Humanity’s Last Exam scores for GPT-5.5 and Gemini 3.1 Pro are approximate from third-party sources; Anthropic’s official chart shows Opus 4.8 as the leader.
Breaking Down Each Benchmark
1. Agentic Coding — SWE-Bench Pro (Real GitHub Issues)
SWE-Bench Pro is widely regarded as the most meaningful coding benchmark because it uses real GitHub issues with multi-file context, legacy code, and vague bug descriptions — not toy problems. Opus 4.8 leads convincingly at 69.2%, nearly 11 percentage points ahead of GPT-5.5.
India relevance: Indian SaaS teams and freelance developers using Claude Code will see a direct productivity gain here. The 4.9-point jump over Opus 4.7 is meaningful for multi-day agentic coding sessions.
2. Terminal-Bench 2.1 — The One Win for GPT-5.5
GPT-5.5 holds its ground on CLI/terminal workflows at 78.2%, edging Opus 4.8’s 74.6%. For DevOps engineers, backend developers, and infra teams working primarily in terminal environments, this benchmark matters. GPT-5.5 is designed for long-running autonomous tasks with tool orchestration — and that shows here.
3. Agentic Computer Use — OSWorld-Verified
Computer use — where an AI controls a desktop or browser interface — is increasingly critical for enterprise automation. Opus 4.8 leads at 83.4%, with GPT-5.5 at 78.7% and Gemini at 76.2%. For Indian enterprises exploring AI-powered RPA (Robotic Process Automation) alternatives, Opus 4.8 is the clear leader.
4. Humanity’s Last Exam — Multidisciplinary Reasoning
This benchmark tests graduate-level reasoning across science, math, law, and humanities. Opus 4.8 scores 57.9% with tools — the highest in the field. This matters for knowledge workers, analysts, and research teams who need a model that can reason across domains without specialised prompting.
5. GDPval-AA — The Real-World Stress Test
Perhaps the most underreported benchmark in this launch. GDPval-AA measures agentic performance across 44 occupations and 9 industries using real-world web and shell access tasks. Opus 4.8 scores 1890 Elo — 121 points ahead of GPT-5.5’s 1769. That gap translates to roughly a 67% head-to-head win rate, according to Anthropic’s released chart. For enterprise deployments, this is the benchmark that matters most.
Pricing and Infrastructure: The Full Picture
Benchmark scores mean nothing without cost context. Here is how the three models compare on pricing and key infrastructure specs:
| Model | Input ($/M) | Output ($/M) | Context Window | Fast Mode |
| Claude Opus 4.8 | $5 | $25 | 1M tokens | 2.5x speed, 3x cheaper |
| GPT-5.5 | $5 | $30 | 256K tokens | Not published |
| Gemini 3.1 Pro | $2–$4* | $12–$18* | 2M tokens | — |
*Gemini 3.1 Pro pricing doubles above 200K tokens ($4/$18 per M tokens). | GPT-5.5 Pro tier: $30 input / $180 output — not compared here.
| 💡 India cost note: At current exchange rates (~₹95/$), running Opus 4.8 at standard pricing costs approximately ₹475 per million input tokens and ₹2,375 per million output tokens. Prompt caching can reduce costs by up to 90%, making Opus 4.8 more competitive with Gemini 3.1 Pro for cached workloads. |
New Features: What Opus 4.8 Brings Beyond Benchmarks
Dynamic Workflows (Research Preview)
The most significant new capability alongside Opus 4.8. Available for Claude Code on Enterprise, Team, and Max plans, Dynamic Workflows allows Claude to plan a task and deploy hundreds of parallel subagents in a single session. Anthropic demonstrated codebase-scale migrations across hundreds of thousands of lines of code. This is Anthropic’s answer to OpenAI’s operator-style multi-agent frameworks — and it is available now.
Effort Control
Available in Claude.ai and Claude Cowork, Effort Control lets users specify how much compute Claude spends on a task. Extra effort (labelled “xhigh” in Claude Code) is recommended for complex, long-running tasks; lower effort for quick queries. Anthropic increased Claude Code rate limits to accommodate higher token usage at elevated effort levels.
Fast Mode
Opus 4.8 Fast Mode runs at approximately 2.5x the speed of standard Opus 4.8 and is priced at one-third the previous Opus 4.7 equivalent. Developers can activate it using the /fast command in Claude Code. API access is available via waitlist.
Decision Guide: Which Model Should You Use?
No single model wins across all use cases. Here is a practical routing framework:
| Use Case | Best Model | Why |
| Agentic coding / Claude Code | Claude Opus 4.8 | SWE-Bench Pro leader; self-correcting; 1M context |
| Terminal / CLI workflows | GPT-5.5 | Leads Terminal-Bench 2.1 at 78.2% |
| Long-document analysis (>200K) | Gemini 3.1 Pro | 2M context at lowest frontier cost |
| Computer use / browser agents | Claude Opus 4.8 | OSWorld-Verified leader at 83.4% |
| Compliance / legal / medical | Claude Opus 4.8 | Lowest hallucination rate; flags uncertainty |
| Multilingual tasks | Gemini 3.1 Pro / GPT-5.5 | Opus 4.8 trails on multilingual benchmarks |
| Cost-sensitive bulk workloads | Gemini 3.1 Pro | Cheapest frontier option at $2/M input |
| 📌 For Indian AI teams: The most cost-effective strategy is a two-model setup — Claude Opus 4.8 for agentic coding, reasoning, and compliance tasks + Gemini 3.1 Pro for long-document analysis and bulk inference. GPT-5.5 is worth evaluating only if your workflows are predominantly CLI/terminal-heavy. |
What Is Coming Next: Mythos-Class Models
Anthropic used the Opus 4.8 announcement to formally tease its next model tier: Mythos-class models. The company has been testing Mythos with a small number of organisations and says it expects to bring Mythos-class models to all customers “in the coming weeks.” Alignment assessments already show that Opus 4.8’s rates of misaligned behaviour are similar to the Claude Mythos Preview — suggesting Mythos will primarily differentiate on capability, not safety metrics.
What to watch: if Mythos represents a meaningful capability leap above the current Opus line, it could render this comparison table obsolete before the end of Q2 2026.
Frequently Asked Questions
Is Claude Opus 4.8 better than GPT-5.5?
Yes, across most benchmarks. Opus 4.8 leads on agentic coding (SWE-Bench Pro: 69.2% vs 58.6%), computer use (83.4% vs 78.7%), and real-world agentic tasks (GDPval-AA: 1890 vs 1769 Elo). GPT-5.5 leads only on terminal/CLI coding and multilingual tasks.
Which AI model is best for coding in 2026?
For agentic, issue-level coding, Claude Opus 4.8 leads with 69.2% on SWE-Bench Pro and 88.6% on SWE-Bench Verified. For terminal/CLI-intensive workflows, GPT-5.5 holds a slight edge at 78.2% on Terminal-Bench 2.1.
How much does Claude Opus 4.8 cost?
Claude Opus 4.8 is priced at $5 per million input tokens and $25 per million output tokens — unchanged from Opus 4.7. The new Fast Mode is approximately 3x cheaper, with up to 90% savings via prompt caching and 50% via batch processing.
What is Claude Opus 4.8’s context window?
Claude Opus 4.8 supports a 1 million token context window on the Anthropic API, Amazon Bedrock, and Google Vertex AI. GPT-5.5 supports 256K tokens. Gemini 3.1 Pro supports 2 million tokens.
Which AI model should Indian developers use?
For agentic coding and reliability-critical applications: Claude Opus 4.8. For cost-sensitive, high-volume inference or long-document tasks: Gemini 3.1 Pro. For terminal/CLI-heavy DevOps workflows: GPT-5.5.
Bottom Line
Claude Opus 4.8 is the most capable generally available AI model as of May 2026 across the benchmarks that matter most for enterprise and developer workloads — agentic coding, computer use, and real-world task performance. It is not a revolutionary leap over Opus 4.7, but it is the right default choice for most AI-native teams. GPT-5.5 earns a spot in any team’s toolkit for terminal workflows. Gemini 3.1 Pro remains the most cost-efficient frontier option for long-document and bulk inference use cases.
The next major shift will come when Anthropic ships Mythos-class models. Until then, Opus 4.8 sets the standard.
Sethu Ram is a search strategist with 16+ years of experience in international SEO across EMEA, APAC, MENA, and North America. He runs WorthView as a live lab for GEO and AI search experimentation, covering the intersection of generative AI, search evolution, and what it means for publishers navigating the post-blue-link web. He is also the founder of MoneyHulk, a personal finance publication for Indian audiences.






