
After months of leaks, false starts, and a rumour that fizzled into Sonnet 4.6 back in February, Anthropic has officially shipped Claude Sonnet 5 — and this time, it’s real.
What Is Claude Sonnet 5?
Anthropic launched Claude Sonnet 5 on June 30, 2026, calling it the most agentic Sonnet model the company has built. In Anthropic’s own framing, it can make plans, use tools like browsers and terminals, and run autonomously at a level that, just a few months ago, required larger and more expensive models.
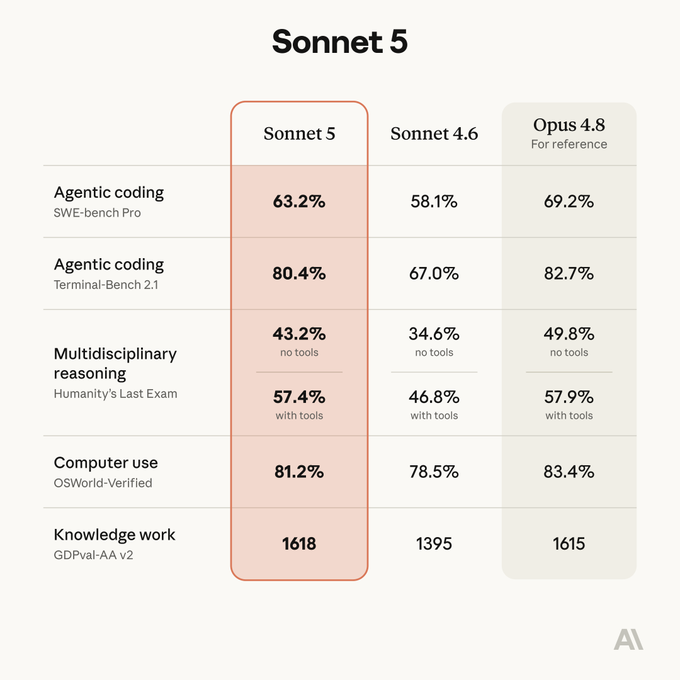
That framing matters. Historically, Anthropic’s Sonnet line was the workhorse tier — capable, but a clear step behind the flagship Opus models on the hardest agentic tasks. Sonnet 5 changes that positioning: its performance is close to Opus 4.8, but at meaningfully lower prices, marking a substantial improvement over its predecessor, Sonnet 4.6, on reasoning, tool use, coding, and knowledge work.
For context, Anthropic credits the Sonnet line with kickstarting the agentic AI era in the first place, with Sonnet 3.5, 3.6, and 3.7 introducing the first genuinely impressive coding and tool-use skills, before the clearest agentic gains shifted to the Opus tier. Sonnet 5 is explicitly pitched as narrowing that gap again.
Key Takeaways
- Claude Sonnet 5 launched officially on June 30, 2026, as Anthropic’s most agentic Sonnet model yet.
- It performs close to Opus 4.8 on agentic benchmarks, at a much lower price point.
- Introductory pricing is $2/$10 per million tokens (input/output) through August 31, 2026, rising to $3/$15 afterward.
- It’s the new default model for Free and Pro plans, and available across Max, Team, Enterprise, Claude Code, and the Claude Platform.
- Anthropic deliberately kept its cybersecurity capability well behind Opus 4.8 and Mythos 5, shipping it with default cyber safeguards.
- It launched alongside Claude Science, on a single high-output news day for Anthropic ahead of its expected IPO.
Key Specs and Pricing
| Launch date | June 30, 2026 |
| API model name | claude-sonnet-5 |
| Introductory pricing | $2 / million input tokens, $10 / million output tokens (through August 31, 2026) |
| Standard pricing (from Sept 1) | $3 / million input tokens, $15 / million output tokens |
| Comparison – Opus 4.8 pricing | $5 / million input tokens, $25 / million output tokens |
| Default model on | Free and Pro plans |
| Also available on | Max, Team, Enterprise, Claude Code, and the Claude Platform (incl. Managed Agents) |
| Tokenizer | Updated tokenizer (same change introduced with Opus 4.7); same input may map to 1.0–1.35x more tokens, offset by introductory pricing |
| Cyber safeguards | Enabled by default, same tier as Opus 4.7/4.8 (less strict than Fable 5’s) |
What’s Actually New
Closing the gap with Opus, not matching it
Anthropic is careful not to overclaim here: Opus 4.8 remains the model of choice for the highest accuracy on hard agentic benchmarks like BrowseComp (agentic search) and OSWorld-Verified (computer use). What Sonnet 5 does is compress the cost-performance curve — where Sonnet 4.6 fell well short of Opus 4.8, Sonnet 5 and Opus 4.8 now sit on a single performance range, with Sonnet 5 offering strong capability at a fraction of the price and Opus 4.8 reserved for when extra accuracy is worth paying for.
Follow-through on multi-step work
Early access partners highlighted Sonnet 5’s tendency to finish complex tasks end-to-end rather than stalling partway, and to check its own output without being explicitly asked to. Anthropic’s own example: handed a two-part job updating Salesforce account tiers and sending a launch announcement to enterprise contacts, the model completed both steps without intervention — a workflow that previously required manual hand-holding.
Safer in agentic contexts
On Anthropic’s pre-deployment safety evaluations, Sonnet 5 showed an overall lower rate of undesirable behaviour than Sonnet 4.6: better at refusing malicious requests, more resistant to prompt-injection hijack attempts, and showing lower rates of hallucination and sycophancy. On Anthropic’s automated behavioural audit covering misuse cooperation and deception, Sonnet 5 scored safer than Sonnet 4.6, though it still showed somewhat higher rates of misaligned behaviour than the more capable Opus 4.8 and Claude Mythos Preview.
Deliberately limited on cybersecurity
Anthropic says it did not deliberately train Sonnet 5 on cybersecurity tasks. In an exploit-development evaluation built with Mozilla on Firefox vulnerabilities, neither Sonnet 4.6 nor Sonnet 5 could produce a working exploit, though Sonnet 5 showed a slightly higher partial-success rate — attributed to general intelligence gains rather than targeted training. Because of this small uptick, Anthropic shipped Sonnet 5 with the same real-time cyber safeguards used on Opus 4.7 and 4.8, though less strict than the safeguards applied to Fable 5.
Why the Timing Is Notable
Sonnet 5 lands just nine days after the U.S. government’s export control directive suspended access to Claude’s flagship Fable 5 and Mythos 5 models for foreign nationals — a directive Anthropic is still navigating. By shipping a model that is deliberately positioned as strong on coding and reasoning but weak on dangerous cyber capability, Anthropic appears to be threading a needle: delivering a major capability upgrade to the broadest possible user base (it’s the new default for Free and Pro users) without reigniting the kind of national-security scrutiny that hit Fable 5 and Mythos 5.
It also arrives the same day as Claude Science, Anthropic’s new AI workbench for scientific researchers — making June 30, 2026 a notably dense news day for the company, and underscoring how aggressively Anthropic is shipping ahead of its anticipated IPO.
How This Plays Out Against the Rumour Mill
It’s worth recapping how messy the run-up to this launch was, because it’s a useful case study in AI-news hygiene. A claude-sonnet-5 identifier first leaked on Google Vertex AI logs back in February 2026 under the codename “Fennec,” triggering weeks of speculative coverage claiming a launch was imminent. That slug ultimately shipped as Sonnet 4.6, not Sonnet 5 — a reminder that internal model identifiers are staging labels, not release calendars.
The same pattern repeated in June: renewed claude-sonnet-5 sightings on partner platforms fuelled another wave of “imminent launch” posts, mixed with recycled specification claims (some borrowed from Fable 5’s tokenizer change) and unverifiable benchmark numbers. This time, the rumours happened to be directionally correct, but the actual announcement — confirmed via Anthropic’s own newsroom and the official @claudeai account — differs in specifics from most of what circulated beforehand, including pricing and context-window claims.
Frequently Asked Questions
Is Claude Sonnet 5 better than Opus 4.8?
Not quite — Opus 4.8 remains Anthropic’s most accurate model on the hardest agentic benchmarks. Sonnet 5 narrows the gap significantly while costing less, making it the better choice for most day-to-day work where Opus-level accuracy isn’t essential.
How much does Claude Sonnet 5 cost?
It launches at introductory pricing of $2 per million input tokens and $10 per million output tokens through August 31, 2026, after which standard pricing of $3/$15 per million tokens applies.
Is Claude Sonnet 5 available for free users?
Yes. It’s the new default model for both Free and Pro plans, and is also available to Max, Team, and Enterprise users, as well as in Claude Code and on the Claude Platform.
Does Claude Sonnet 5 have a 1 million token context window?
Anthropic’s official announcement does not specify a 1M-token context window for Sonnet 5; that figure circulated widely in pre-launch rumours but isn’t confirmed in the official launch materials, so readers should treat it as unverified until Anthropic’s documentation confirms it.
Why did Sonnet 5 take so long to confirm?
A model identifier matching Sonnet 5 leaked as early as February 2026, but that build ultimately shipped as Sonnet 4.6. A second wave of leaks in June 2026 preceded the actual confirmed launch on June 30.
Sethu Ram is a search strategist with 16+ years of experience in international SEO across EMEA, APAC, MENA, and North America. He runs WorthView as a live lab for GEO and AI search experimentation, covering the intersection of generative AI, search evolution, and what it means for publishers navigating the post-blue-link web. He is also the founder of MoneyHulk, a personal finance publication for Indian audiences.






